Opinion Mining
Introduction
Opinion mining is a type of natural language processing for tracking the mood of the public about a particular product.
Opinion mining, which is also called sentiment analysis, involves building a system to collect and categorize opinions about a product. Automated opinion mining often uses machine learning, a type of artificial intelligence (AI), to mine text for sentiment.
Opinion mining can be useful in several ways. It can help marketers evaluate the success of an ad campaign or new product launch, determine which versions of a product or service are popular and identify which demographics like or dislike particular product features. For example, a review on a website might be broadly positive about a digital camera, but be specifically negative about how heavy it is. Being able to identify this kind of information in a systematic way gives the vendor a much clearer picture of public opinion than surveys or focus groups do, because the data is created by the customer.
What i used to build the system
- HTML,CSS,Javascript
- Anaconda with python 2.7
- External Python Libraries
- NTLK Natural language processing toolkit library
- TwitterSearch Twitter Tweets Grabber
How The System Works
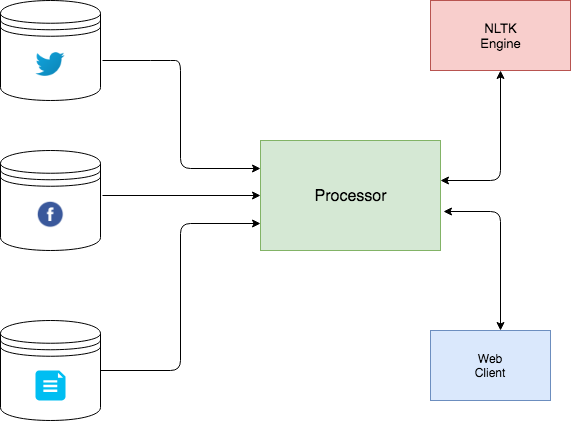
The system contains three main components
- NLTK Engine
- Web Client for User Interface
- Processor
The NLTK Engine works on fetched texts by extracting sentiments and opinions.
The Web Client is used by the user to upload or gather data from multiple sources and view the extracted sentiments from the NLTK engine. The webclient is written in html,css and javascript.
The Processor is used to gather data from facebook,twitter or local files containing reviews or comments and feeds them to the NLTK engine. After the NLTK engine extracts the sentiments, the processor using the builtin small server will forward the results to the connected webclient. The processor is written in python.
The Web Client
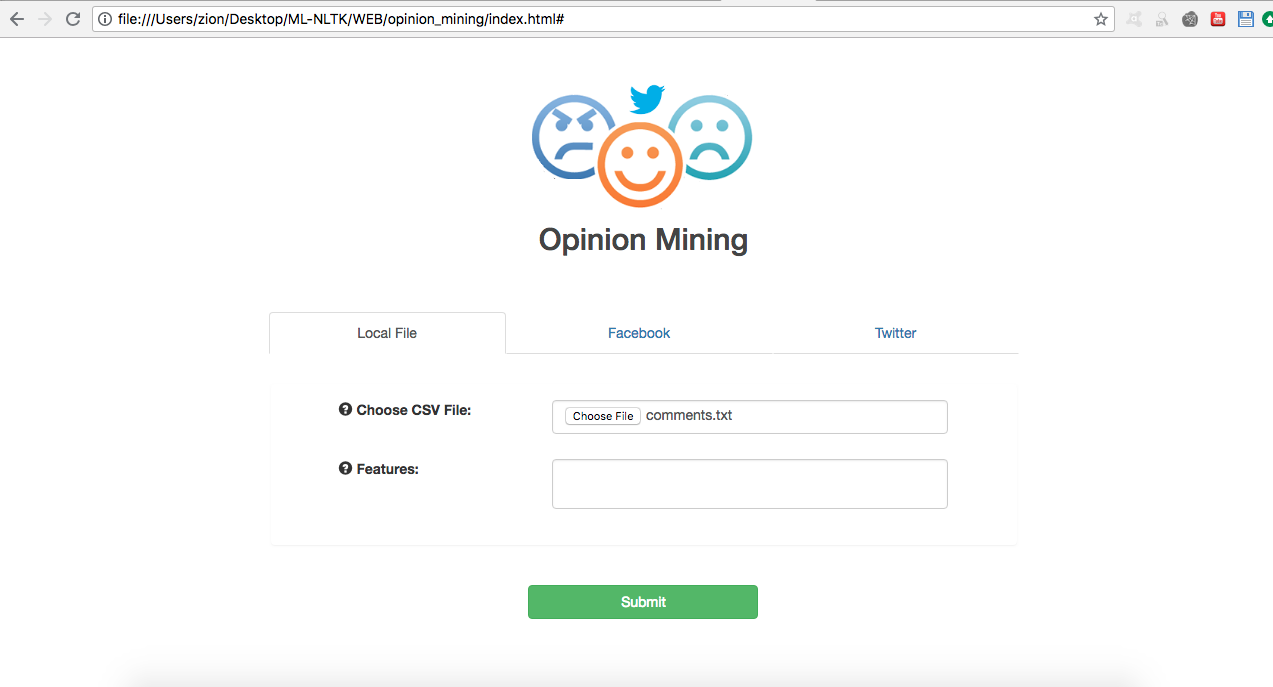
The above image shows the screenshot of first page that appears when the webclient is launched. The first process of performing opinion mining involves choosing a datasource. To select data sources the first page has three tabs (Local file, Facebook and Twitter). In Local File tab, the user can browse local files and type in features.
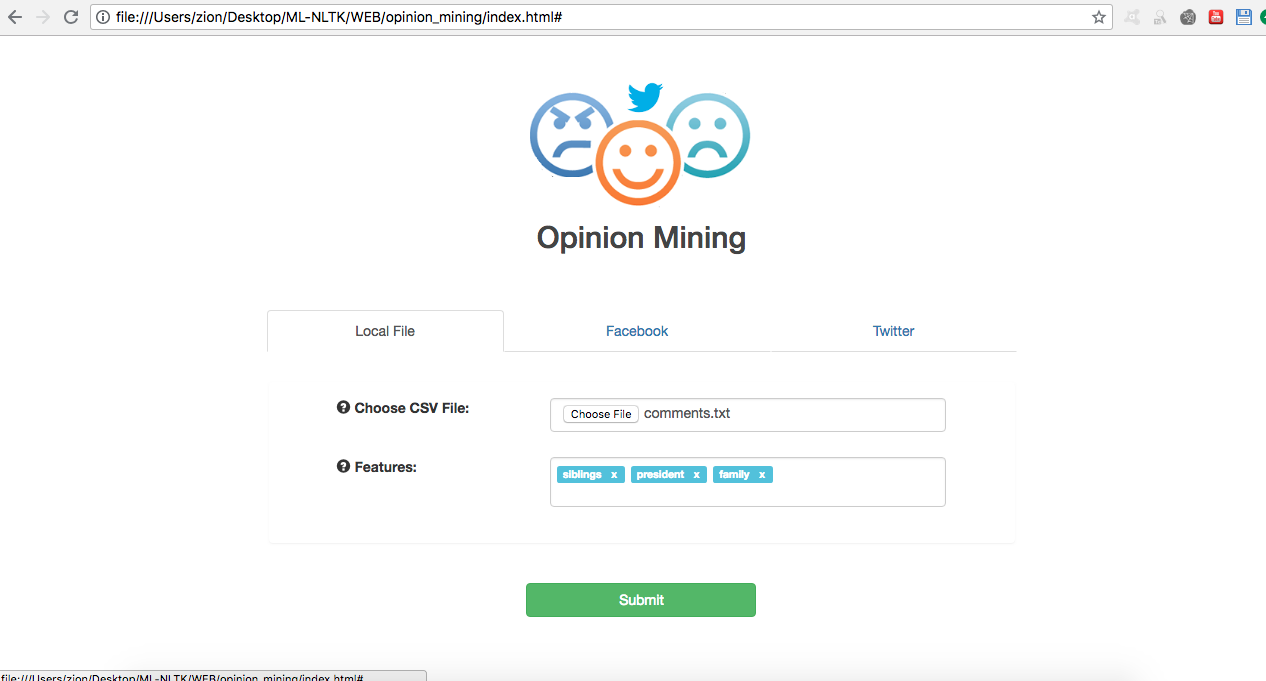
Features are a group of keywords that the user types that
are used to extract particular points from the opinions.
For example, If the user uploads digital camera reviews,
the user might want to extract opinions about specific
features like weight, size, picture quality etc... Therefore
by typing "weight", "size", "picture quality" in the features
textbox the processor will extract the opinions in the reviews
that are talking about those listed features.
Typed features are showen below.
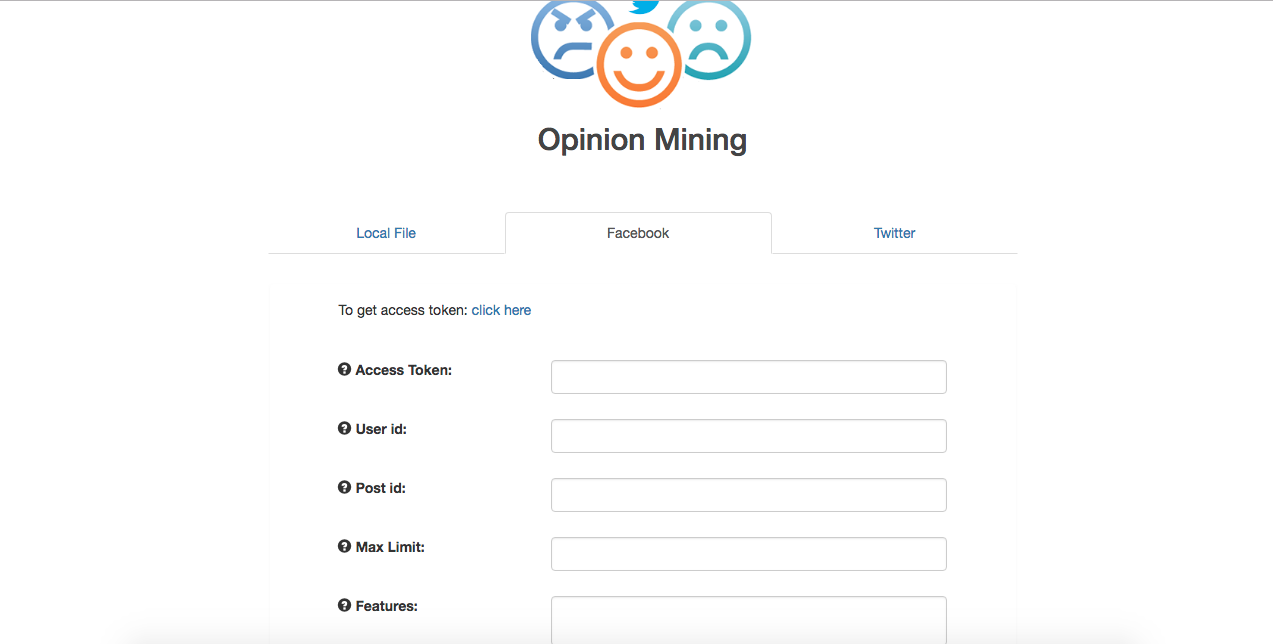
To access facebook data the user is required to fill the form shown below.
To access twitter data the user is required to fill the form shown below.
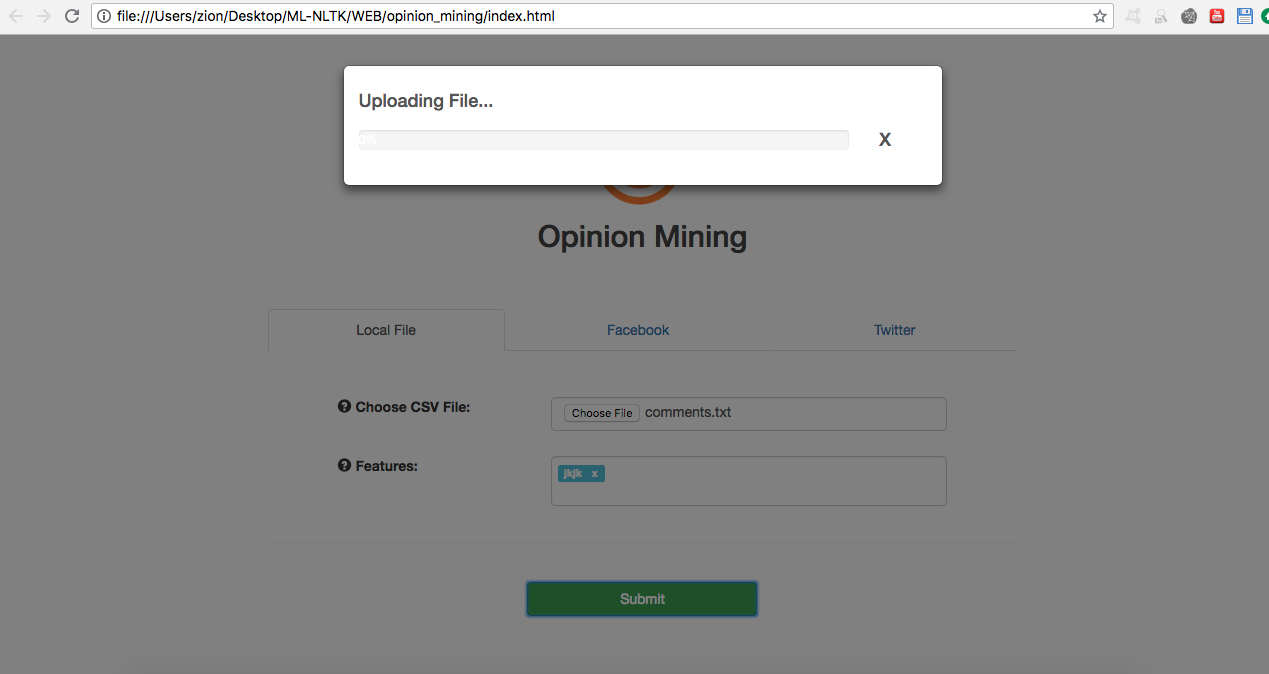
After the datasource is located and the user hits the Submit button, the processor will start to upload the data if it’s from a local storage or access fb and twitter servers to access posts and tweets.
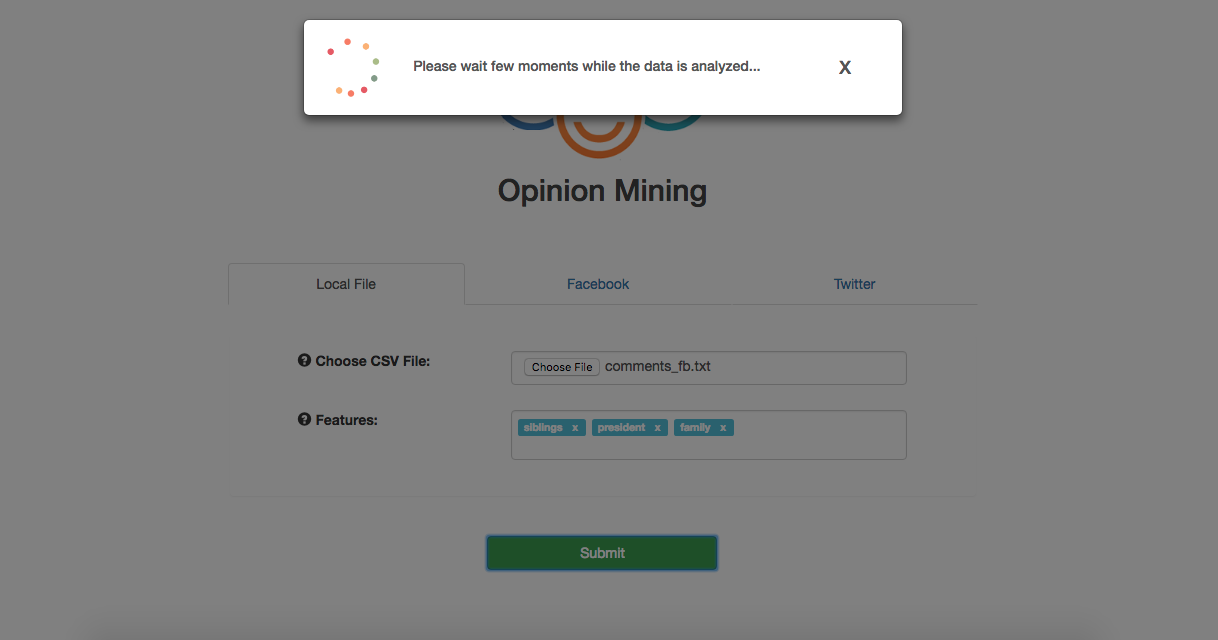
After the processor successfully gathers reviews, it will launch the NLTK engine to process the fetched data.
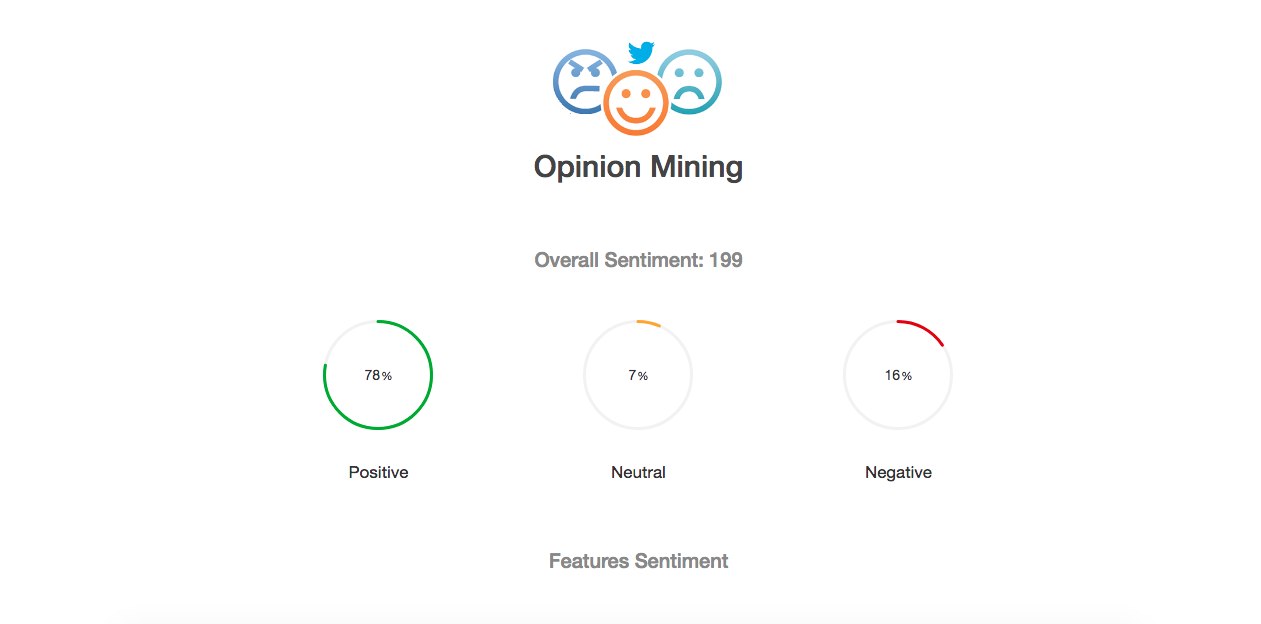
Once the opinions are extracted, a new page is opens to display the analysis results.
Scrolled down image
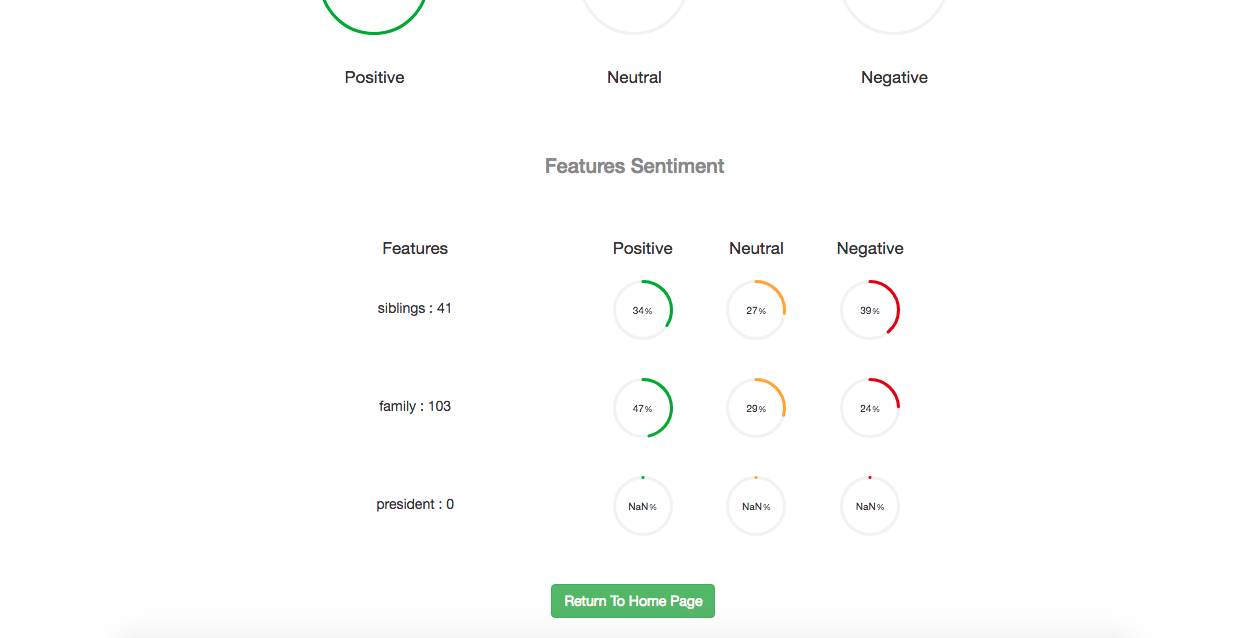
As you can see in the above two images, On the top page we have a general sentiment towards the product. And in the Features Sentiments, we have each feature’s sentiment and the number of mentions in the review.
To launch the system
1. source activate <ENV NAME>
2. cd path\to\project\folder\SERVER
3. python op_server.py
4. Go to WEB folder and click index.html
You can now use the application
You can find the source code of this project here.